
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- heap
- django
- 탐욕법
- 동적계획법
- 완전탐색
- binary search
- Code Refactoring
- programmers
- Algorithm
- BFS
- DVWA
- 코딩테스트
- 힙
- Greedy
- DP
- 알고리즘
- Queue
- string
- 그래프
- 백준
- 프로그래머스
- graph
- DFS
- Dynamic Programming
- 정렬
- Brute Force
- sort
- 카카오 기출
- 문자열
- 큐
- Today
- Total
생각과 고민이 담긴 코드
프로그래머스 - 디스크 컨트롤러 (Heap) / Level 3 본문
문제 설명
하드디스크는 한 번에 하나의 작업만 수행할 수 있습니다.
디스크 컨트롤러를 구현하는 방법은 여러 가지가 있습니다.
가장 일반적인 방법은 요청이 들어온 순서대로 처리하는 것입니다.
예를 들어
- 0ms 시점에 3ms가 소요되는 A작업 요청 - 1ms 시점에 9ms가 소요되는 B작업 요청 - 2ms 시점에 6ms가 소요되는 C작업 요청과 같은 요청이 들어왔습니다.
이를 그림으로 표현하면 아래와 같습니다.
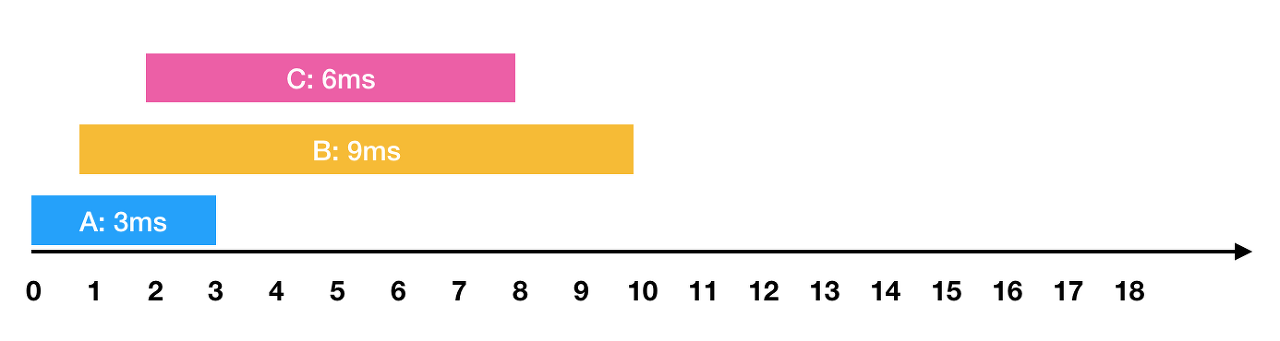
한 번에 하나의 요청만을 수행할 수 있기 때문에 각각의 작업을 요청받은 순서대로 처리하면 다음과 같이 처리됩니다.

- A: 3ms 시점에 작업 완료 (요청에서 종료까지 : 3ms)
- B: 1ms부터 대기하다가, 3ms 시점에 작업을 시작해서 12ms 시점에 작업 완료(요청에서 종료까지 : 11ms)
- C: 2ms부터 대기하다가, 12ms 시점에 작업을 시작해서 18ms 시점에 작업 완료(요청에서 종료까지 : 16ms)
이때 각 작업의 요청부터 종료까지 걸린 시간의 평균은 10ms(= (3 + 11 + 16) / 3)가 됩니다.
하지만 A → C → B 순서대로 처리하면

- A: 3ms 시점에 작업 완료(요청에서 종료까지 : 3ms)
- C: 2ms부터 대기하다가, 3ms 시점에 작업을 시작해서 9ms 시점에 작업 완료(요청에서 종료까지 : 7ms)
- B: 1ms부터 대기하다가, 9ms 시점에 작업을 시작해서 18ms 시점에 작업 완료(요청에서 종료까지 : 17ms)
이렇게 A → C → B의 순서로 처리하면 각 작업의 요청부터 종료까지 걸린 시간의 평균은 9ms(= (3 + 7 + 17) / 3)가 됩니다.
각 작업에 대해 [작업이 요청되는 시점, 작업의 소요시간]을 담은 2차원 배열 jobs가 매개변수로 주어질 때,
작업의 요청부터 종료까지 걸린 시간의 평균을 가장 줄이는 방법으로 처리하면 평균이 얼마가 되는지
return 하도록 solution 함수를 작성해주세요. (단, 소수점 이하의 수는 버립니다)
제한 사항
- jobs의 길이는 1 이상 500 이하입니다.
- jobs의 각 행은 하나의 작업에 대한 [작업이 요청되는 시점, 작업의 소요시간]입니다.
- 각 작업에 대해 작업이 요청되는 시간은 0 이상 1,000 이하입니다.
- 각 작업에 대해 작업의 소요시간은 1 이상 1,000 이하입니다.
- 하드디스크가 작업을 수행하고 있지 않을 때에는 먼저 요청이 들어온 작업부터 처리합니다.
입출력 예시
| jobs | return |
| [[0, 3], [1, 9], [2, 6]] | 9 |
입출력 예 설명
문제에 주어진 예와 같습니다.
- 0ms 시점에 3ms 걸리는 작업 요청이 들어옵니다.
- 1ms 시점에 9ms 걸리는 작업 요청이 들어옵니다.
- 2ms 시점에 6ms 걸리는 작업 요청이 들어옵니다.
풀이
def solution(jobs):
answer = 0
time = 0
jobs_len = len(jobs)
jobs.sort(key=lambda x: (x[1], x[0])) # 작업 소요시간 순으로 정렬하고 같으면 도착 시간순으로 정렬.
while len(jobs) != 0:
for i in range(len(jobs)):
if jobs[i][0] <= time: # 현재 시각 기준 도착해있는 것들 중 가장 소요시간 짧은거(이미 정렬됨) 선택해서 처리.
answer += (time - jobs[i][0] + jobs[i][1]) # 총 작업시간 계산해서 저장.
time += jobs[i][1] # 선택한 작업 반영하여 현재 시각 초기화.
jobs.remove(jobs[i])
break
if i == len(jobs) - 1: # 현재 시각 기준 도착한 작업이 없으면 1초 대기.
time += 1
answer = answer // jobs_len
return answer레벨 3 문제로 OS의 Process Scheduling 기법 중 하나인 SJF(Shortest Job First) 기법을 대상으로 한 문제이다.
조건과 경우의 수가 매우 복잡해 보이지만 결론적으로 생각해보면
어떠한 시점에서 도착해있는 작업들 중 소요시간이 제일 짧은 것을 선택해서 처리해주면 된다.
그래야 뒤에 따라오는 작업의 대기시간이 짧아져 전체 평균 처리시간이 짧아지기 때문이다.
추가적으로 SJF 기법은 실제 OS에서 사용되는 기법이 아닌 이론상으로만 존재하는 이상적인 Scheduling 기법이다.
현실에서는 Process의 작업 시간을 정확히 예측하는 것은 불가능에 가깝기 때문에
일정 Time Quantum 만큼 process들을 preemptive(선점적으로) 하게 실행시켜주는 Round Robin 기법 등이 쓰인다.
(조금 더 깊이 들어가자면 Priority가 적용된 Multilevel Queue Scheduling과 Round Robin이 같이 쓰인다.)
이 문제가 왜 Heap 분류에 속해 있을까?
처리시간 평균이 최소가 되기 위해 Job들을 소요시간이 최소가 되도록 정렬할 필요가 있었다.
비록 정렬 시점이 반복문 안이 아니여서 heap을 안 써도 되었지만
만약 반목문 안에서 정렬을 해야 되었다면 Heap을 사용하여 시간복잡도를 낮춰야 했을 것이다.
'Algorithm > 프로그래머스' 카테고리의 다른 글
| 프로그래머스 - K번째 수 (정렬) / Level 1 (0) | 2021.08.21 |
|---|---|
| 프로그래머스 - 이중우선순위큐(Heap) / Level3 (0) | 2021.08.16 |
| 프로그래머스 - 더 맵게(Heap) / Level 2 (4) | 2021.08.09 |
| 프로그래머스 - 주식가격(Stack/Queue) / Level 2 (0) | 2021.08.08 |
| 프로그래머스 - 다리를 지나는 트럭(Stack / Queue) / Level 2 (0) | 2021.08.07 |
